- HOME
- All Products
- Lessons from the CrowdStrike incident and comprehensive response strategies
Lessons from the CrowdStrike incident and comprehensive response strategies
- Published : August 2, 2024
- Last Updated : August 22, 2024
- 1.6K Views
- 7 Min Read
In the era of advanced technology, unexpected IT and cybersecurity incidents can severely disrupt business operations. The CrowdStrike incident on July 19, 2024 serves as a stark reminder that no system is infallible. CrowdStrike, a leading endpoint security solutions provider, released an update for its Falcon sensor, which inadvertently triggered a catastrophic chain of events. A logic error in the configuration file led to a kernel panic, manifesting as the infamous blue screen of death (BSOD) across Windows endpoints. This unforeseen event brought operations to a grinding halt, affecting businesses and users globally.
The importance of comprehensive response strategies
An effective approach to managing major disruptions or cyberattacks comprises three essential components:
Incident response: Immediate actions to stabilize operations, including identifying critical systems, assessing the impact of disruptions, and implementing containment measures.
Planning for business continuity: Ensuring ongoing operations during and after an incident by transitioning to resilient infrastructure, maintaining high availability, and executing comprehensive backup and recovery plans.
Post-incident measures: Long-term strategies to prevent future incidents, including conducting root cause analysis, updating risk registers, enhancing quality assurance, and providing ongoing training.
Let's look at each of these strategies in detail.
Incident response
Identify critical systems
Different organizations have their own set of critical systems that are essential for operations, such as customer databases, transaction processing systems, healthcare management systems, workplace application suite, and more. To identify these systems, a cross-functional team involving IT professionals, business continuity planners, and departmental representatives should conduct a business impact analysis (BIA). This process helps determine vital systems and their dependencies.
For example, if email or team chat services are disrupted, not only will it affect customer communication and internal collaboration as well as vital operations that rely on workflows integrated with these apps (such as transaction processing), but ticketing could be severely affected.
Email admins can designate email servers and workplace applications as critical configuration items (CIs) in the configuration management database (CMDB). This applies to both on-premise and cloud-based services. For on-premise services, include hardware details, software versions, and network configurations. For cloud services, document the service configurations, dependencies, and SLAs provided by the cloud vendor.
Assess impact
Evaluate the impact of disruptions by determining how many endpoints are affected and which critical functions are compromised. Engage IT staff, business continuity planners, and departmental representatives to prioritize response efforts. Assess how disruptions in email or team chat services affect customer communication and internal workflows, such as transaction processing and support ticketing.
Mitigation and containment
Organizations must isolate systems affected by the CrowdStrike incident to prevent the spread of the faulty update. This involves halting the deployment of the problematic update and disconnecting affected systems from the network to contain the disruption. Apply emergency patches or revert to previous stable software versions to restore stability. IT teams should work closely with security experts to implement these measures swiftly, ensuring minimal downtime and preventing further spread of the issue.
Continuous monitoring
Implement real-time monitoring for both on-premise and cloud-based email and workplace services. The SOC and IT teams should use advanced tools like intrusion detection systems (IDS), security information and event management (SIEM) systems, and network traffic analyzers to monitor system health. These tools help detect further issues and potential cybersecurity threats. Regularly update and communicate with stakeholders to ensure a coordinated and effective response.
On-Premise Services |
|
Cloud Services |
|

Incident Response
1. The IT team investigates access logs and activities on applications and app servers.
2. They quarantine the disrupted or compromised networks and devices and install patches.
3. Hardware replacement or network reconstruction is carried out with help from the infrastructure management team.
Planning for business continuity
Ensuring business continuity in the wake of incidents like the CrowdStrike disruption is a critical challenge. While the IT infrastructure of an organization is varied and comprehensive, focusing on key systems that keep operations running is essential.
1. Cloud-based and employee mobility
Transitioning critical services like workplace applications (e.g., email service, team chat, video conferencing, file sharing) and applications for their daily operations (e.g., support desk, CRM, HRMs, books and accounting, invoicing) from on-premise servers to cloud-based solutions ensures higher availability. Cloud providers offer geographically distributed data centers, providing redundancy and quick recovery from regional failures. Empowering employees with cloud-based apps that are accessible from laptops, desktops, and mobile phones ensures they're not tied to their desks and can work from anywhere.
2. High availability
High availability (HA) refers to systems designed to be operational and accessible without significant downtime. It ensures that critical services remain available even during hardware failures, software glitches, or other disruptions.
In the context of on-premise email services, high availability is achieved through redundancy, failover mechanisms, and continuous monitoring.
Email continuity services: To ensure high availability for email services, organizations can build redundancy into the service with automatic failover. And to supplement that even further, organizations may implement a cloud email continuity service. This involves several key components and strategies:
Email continuity service: This is a cloud-based system consisting of email security and archival features. When the primary email service experiences downtime, an email continuity service automatically takes over. Users can access their emails via a web portal, ensuring no loss of communication capabilities.
IMAP synchronization: Once the primary service is restored, emails and activities conducted through the continuity service are synchronized back to the primary service using IMAP sync, maintaining data consistency.
Automatic failover: The system is designed to switch to backup servers or services automatically if any part of the primary service fails, ensuring continuous email availability.
Hybrid (on-premise and cloud-based) backup solutions: Combining both on-premise and cloud-based backups provides an additional layer of security and flexibility. This hybrid approach ensures that email data is always available, even if one backup system fails.
Ensuring active directory availability: To maintain business continuity during incidents like the CrowdStrike failure, organizations must ensure that employees' authentication, authorization, and resource access remain uninterrupted. Active directory (AD) is crucial for managing user identities and access permissions. If AD is compromised, users may be unable to log in or access essential services. By ensuring robust AD synchronization and regular backups, enterprises can prevent disruptions in user access and maintain system functionality.

High Availability
3. Plan for backup and recovery
Comprehensive backup and recovery strategies are central to business continuity. Regularly backing up critical data and systems to secure off-site locations ensures preservation during disruptions.
In the context of email services, while backup and recovery, archival, and e-discovery serve different purposes, they collectively ensure effective email system management. Backup and recovery focus on quick restoration, archival handles long-term storage, and e-discovery aids in legal compliance.
| Backup and recovery | Archival | e-discovery |
Purpose | Ensure data preservation and quick restoration in case of data loss or system failure. | Long-term data storage for compliance, historical reference, and space management. | Identify, collect, and produce electronically stored information (ESI) for legal or regulatory inquiries. |
Functionality | Regularly scheduled backups capture current data, which can be restored in emergencies. | Stores data that is no longer actively used but needs to be retained long-term. | Searches through archived data to locate and retrieve specific documents or communications. |
Use case | Recover from incidents like hardware failures, ransomware attacks, or accidental deletion. After a system failure caused by an update error, backup systems restore email services. | Retain emails for legal, regulatory, or historical reasons. Financial institutions archive emails to comply with data retention regulations. | Find all emails related to a specific topic or individual during a legal investigation. Companies use e-discovery to locate and produce relevant email communications during lawsuits. |
In context of CrowdStrike incident | Ensures email communication can be quickly restored after disruptions, maintaining continuity. | Provides long-term email storage for compliance and regulatory needs. | Facilitates legal and regulatory compliance by enabling efficient search and retrieval of emails. |
Tools | Automated backup solutions | Email archival solutions | e-discovery platforms |
Post-incident measures for enterprises
While updating a patch is crucial to resolving immediate issues, enterprises must adopt comprehensive post-incident measures to ensure long-term stability and security. Conducting a root cause analysis (RCA) and implementing corrective action preventive action (CAPA) help understand and prevent future disruptions. Regularly reviewing and updating the risk register, enhancing quality assurance and testing, strengthening patch management, providing ongoing training, and conducting post-incident reviews collectively create a resilient IT environment.
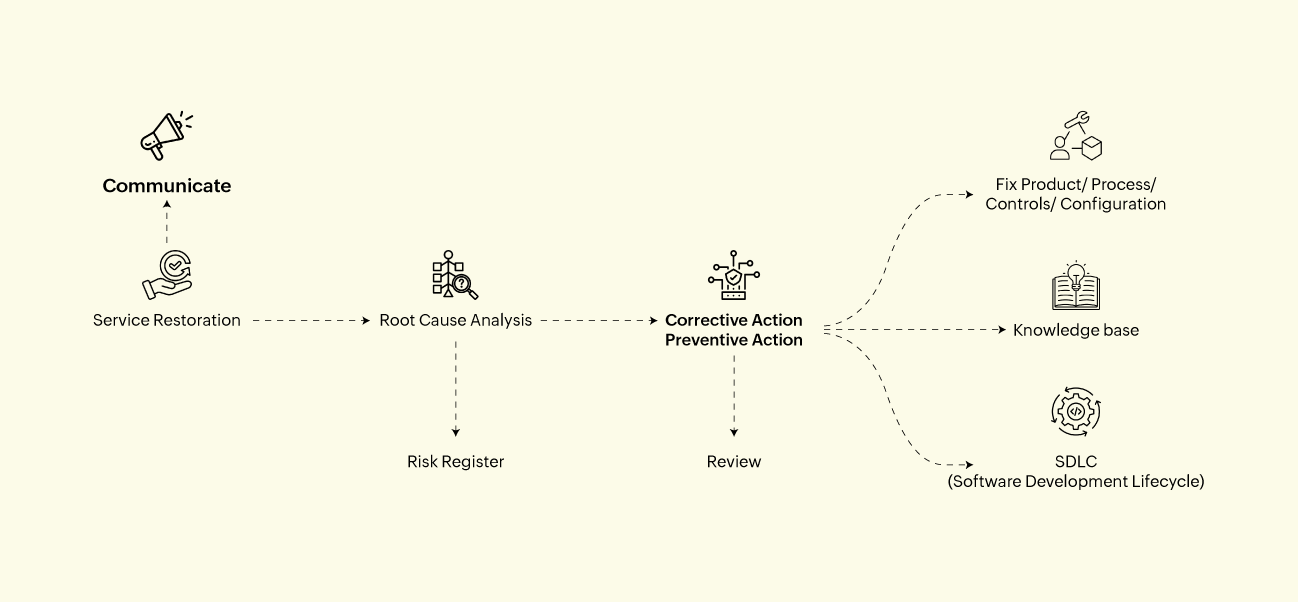
Conclusion
The CrowdStrike incident serves as a crucial lesson in the need for robust IT resilience and business continuity planning. Beyond the technical measures, the human aspect is equally vital. Empowering employees with continuous training on cybersecurity best practices, fostering a culture of vigilance, and ensuring clear communication during crises are essential. Engaged and well-informed staff can identify potential threats early, respond more effectively during disruptions, and contribute to a faster recovery.
Transparent communication: Clearly communicate with stakeholders, including employees, partners, and customers, to maintain trust and manage expectations during disruptions.
Customer-facing protocols: Establish protocols to manage customer inquiries and maintain consistent service during incidents.
Collaborative approach: Ensure coordination across departments for a unified and swift response.
Proactive monitoring and testing: Implement regular system monitoring and testing to identify vulnerabilities and prepare teams for real incidents.
Post-incident reviews: Conduct thorough reviews to learn from incidents and improve future responses.
Employee training: Regularly train employees on cybersecurity practices and response protocols to enhance threat identification and response.


